Importance of Monitoring and Debugging for Data Environments
 Photo by Luke Chesser on Unsplash
Photo by Luke Chesser on Unsplash
In today’s digital transformation era, data takes on the role of new oil. The number of companies and organizations that make decisions and take action based on data is increasing day by day. This situation brings with it both some advantages and disadvantages. At this stage, it is crucial that the data analyzed and interpreted are reliable and consistent in order to help you make the right data-driven decisions.
Manipulating datasets, correcting errors and bugs, or inserting extra data may require creating a new version due to the nature of data analytics. Therefore, data science projects and their architectures are conducted with data lifecycle management to be able to make progress seamless and easy to maintain.
Now, it is necessary to dive into the details of what data lifecycle management is and its basic steps of it to understand how it provides healthy data environments for data analytics.
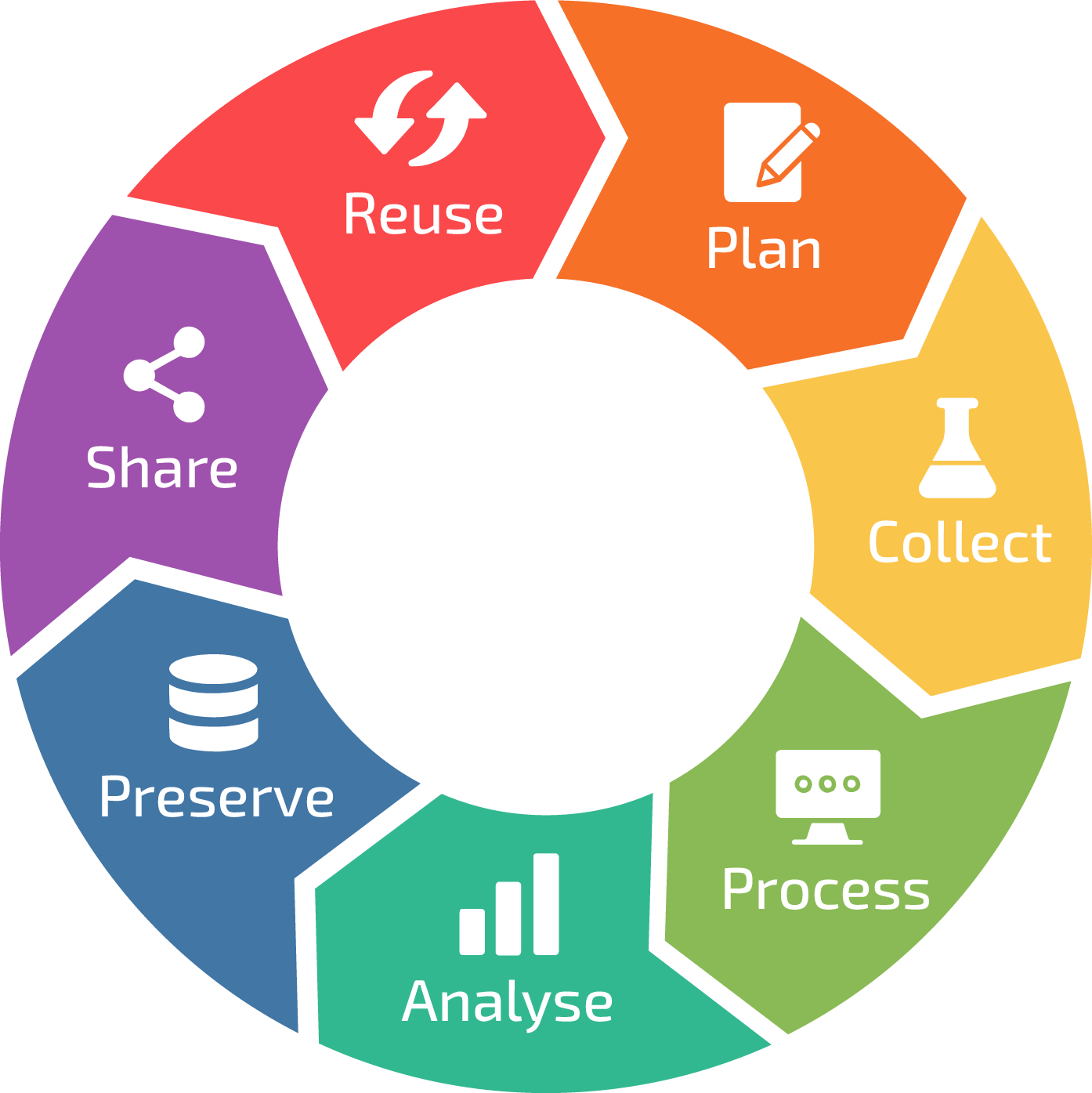
What Is Data Lifecycle Management?
Data lifecycle management can be described as a set of important steps that are applied in end-to-end machine learning (ML) projects. Data teams and similar organizations should reference these steps in every phase of projects to manage the whole process as successfully.
Why Is Data Lifecycle Management Important?
In the era of AI and ML, new technologies and open-source tools leave their place for new ones constantly. Due to this rapid change, there is a need for a management system that can monitor every phase of the project.
The data lifecycle can play an important role as a management system by monitoring and debugging the whole system. It can assist you in testing acquired data reliability and consistency in every step of the ML project. Thus, it might be helpful to take a look at some of the key steps of data lifecycle management.
Basic Steps of Data Lifecycle Management
In general, all data lifecycle management can be divided into four main steps which are:
Data Acquisition
In the modern data infrastructure, new data flows from different data sources continuously, and the process of migrating this data to analytical databases is called data acquisition. As a reminder, analytical databases are generally used for data analytics projects in data teams. This phase can also be called data flow or data ingestion. This step is the first one but can be thought of as the most important one because it is vital to ensure that new data is constantly migrated for a consistent data environment. This can be done successfully by using data orchestration tools.
Data Wrangling
In real-life projects, most of the acquired data is very messy and needs transformation before it can be stored in analytical databases. All steps of data cleaning and preprocessing are called data wrangling. It is an important necessity for flowing healthy data into the analytics project’s environment. In short, the following preprocessing operations can be applied in this stage; handling null or duplicate values, creating data schema for fitting requirements, any aggregation operations for usage in analytics databases, and filtering data according to business demands.
Data Validation
As practiced in the traditional software development methodology, after the data migration and transformation steps are completed, all remaining operations must be verified in order to move on to the next steps. This validation process can be thought of as data quality testing for explaining it more clearly.
There are a variety of techniques that can be applied to the data validation process in practice, but it is smarter to utilize the CI/CD approach as a workflow type. By doing so, migrated data can pass unit, integration, and quality tests as part of the deployment process. This stage is the last step before the end-user. Therefore, everything needs to be seamless.
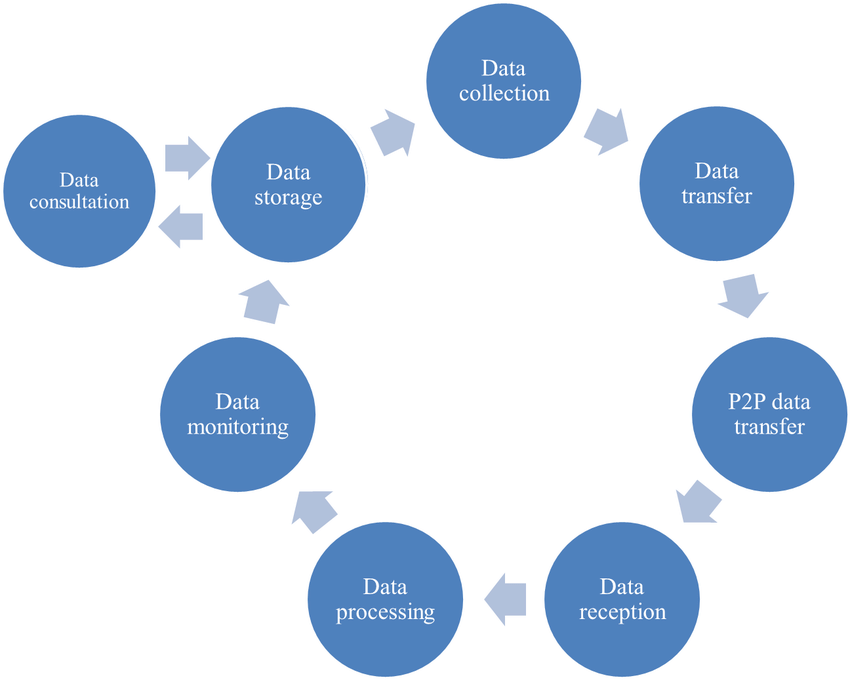
Data Monitoring and Debugging
In the final stage, you should check all the changes and flow in the data environment to ensure all events that occur in the infrastructure are as expected. Data teams need to utilize monitoring and debugging methods in the pipeline to track these changes because any modification in raw data may negatively affect the results of the analytics projects.
For example, let’s say your data analytics team deploys its customer segmentation project into production. Basically, this project makes a real-time stream processing with the data that is ingested from your data environment. You start to track all the changes in a data environment and realize that some bugs and unwanted changes happened in the data via a monitoring alert. Your customer segmentation project can mislead business or operation teams. This situation may result in the loss of your organization if you do not implement monitoring and debugging stages in the data environment.
Conclusion
Every corporation has been continuing to transform into its own digital version and this process will continue to cause the problems mentioned above most of the time. Therefore, you should focus on effective and protective solutions such as data monitoring and debugging for these problems.
I hope you found this article informative and that it helped you decide whether the data monitoring and debugging approach are important for your data infrastructure.
Appreciate the creator